API Reference¶
This section provides detailed documentation of all public modules and classes.
Configuration¶
- class transformer.config.TransformerConfig(n_layers=12, d_model=1536, n_heads=32, n_kv_heads=None, vocab_size=50000, d_ff=None, norm_design='pre_norm', norm_class='rms_norm', ffn_class='SwiGLU', attn_class='MHA', block_class=None, attn_bias=False, ffn_bias=True, lm_head_bias=False, attn_qk_norm=True, attn_dropout=0.0, tied_weights=False, seq_len=1024, pos_encoding='RoPE', rope_base=10000.0, max_seq_len=4096, use_cache=False, is_decoder=True, patch_size=None, img_size=None, in_channels=3, **kwargs)[source]¶
Bases:
PreTrainedConfigConfiguration class for Transformer models. Inherits from PretrainedConfig for HuggingFace compatibility.
- Parameters:
n_layers (int) – Number of Transformer Blocks (layers).
d_model (int) – Model Dimension.
n_heads (int) – Number of Attention Heads.
n_kv_heads (int, optional) – Number of key/value heads for Grouped-Query Attention(GQA). Default:
n_headsvocab_size (int) – Vocabulary size of the model. Defines the number of different tokens.
d_ff (int, optional) – Dimension of the Feed-Forward Hidden Layer.
norm_design (str) – Normalization Design, one of
pre-norm,post-normorboth. Default:pre-normnorm_class (Union[List[Union[Type[nn.Module], str]], Type[nn.Module], str]) –
Normalization class or type. - If
str, one ofrms_normorlayer_norm. - IfType[nn.Module]then will be instantiated inside the model.Should have the same API as a torch Normalization Layer.
If
List[Union[Type[nn.Module], str]]and len(norm_class) == n_layers then will be instantiated inside the model for the corresponding layers.
ffn_class (Union[List[Union[Type[nn.Module], str]], Type[nn.Module], str]) –
Feed-Forward Network class or type. - If
str, one ofSwiGLU,MLP. - IfType[nn.Module]then will be instantiated inside the model.Should have the same API as
SwiGLUandMLP. DefaultSwiGLUIf
List[Union[Type[nn.Module], str]]and len(ffn_class) == n_layers then will be instantiated inside the model for the corresponding layers. DefaultSwiGLUfor every layer.
attn_class (Union[List[Union[Type[nn.Module], str]], Type[nn.Module], str]) –
Attention class or type. - If
str, one ofMHA,GQA,CrossAttention. ForGQA, also specify n_kv_heads. - IfType[nn.Module]then will be instantiated inside the model.Should have the same API as
transformer.attn.MHA. DefaultMHAIf
List[Union[Type[nn.Module], str]]and len(attn_class) == n_layers then will be instantiated inside the model for the corresponding layers. DefaultMHAfor every layer.
block_class (Optional[Type[nn.Module]]) – Transformer Block class for every layer. Default:
None- IfType[nn.Module]then will be instantiated for every layer inside the model. - IfNonethen the defaulttransformer.TransformerBlockwill be usedattn_bias (bool, optional) – Whether to use bias in attention Linear Projections. Default:
Falseffn_bias (bool, optional) – Whether to use bias in Feed-Forward Linear layers. Default:
Truelm_head_bias (bool, optional) – Whether to use bias in the Language Modeling Head. Default:
Falseattn_qk_norm (bool, optional) – Whether to apply Normalization to Queries and Keys before the Attention Computation. Default:
Trueattn_dropout (float, optional) – Dropout probability for the Attention Layer. Default:
0.0tied_weights (bool, optional) – If True, tie the input embedding and output projection weights. Default:
Falseseq_len (int) – Sequence Length.
pos_encoding (Union[List[str], str]) – Positional Encoding for attention. - If
strone ofRoPE,AliBI,PartialRoPE. Default:RoPENote: Is recommended to change the default toPartialRoPEwhich is used in SOTA models like Qwen3-Next-80B-A3B - IfList[str]and len(pos_encoding) == n_layers, applies different positional encodings per layer.rope_base (float, optional) – Base for the Exponential Frequency Calculation in RoPE. Default:
10000.0max_seq_len (int) – Maximum sequence length for positional embeddings.
use_cache (bool, optional) – Whether to use KV cache during generation. Default:
Trueis_decoder (bool, optional) – Whether this is a decoder model. Default:
Truekwargs (dict, optional) – Additional keyword arguments passed to PretrainedConfig
patch_size (int | None)
img_size (int | tuple | None)
in_channels (int)
- model_type = 'transformer'¶
- __init__(n_layers=12, d_model=1536, n_heads=32, n_kv_heads=None, vocab_size=50000, d_ff=None, norm_design='pre_norm', norm_class='rms_norm', ffn_class='SwiGLU', attn_class='MHA', block_class=None, attn_bias=False, ffn_bias=True, lm_head_bias=False, attn_qk_norm=True, attn_dropout=0.0, tied_weights=False, seq_len=1024, pos_encoding='RoPE', rope_base=10000.0, max_seq_len=4096, use_cache=False, is_decoder=True, patch_size=None, img_size=None, in_channels=3, **kwargs)[source]¶
- Parameters:
n_layers (int)
d_model (int)
n_heads (int)
n_kv_heads (int | None)
vocab_size (int)
d_ff (int | None)
norm_design (str)
norm_class (List[Type[Module] | str] | Type[Module] | str)
ffn_class (List[Type[Module] | str] | Type[Module] | str)
attn_class (List[Type[Module] | str] | Type[Module] | str)
block_class (Type[Module] | None)
attn_bias (bool)
ffn_bias (bool)
lm_head_bias (bool)
attn_qk_norm (bool)
attn_dropout (float | None)
tied_weights (bool)
seq_len (int)
pos_encoding (List[str] | str)
rope_base (float)
max_seq_len (int)
use_cache (bool)
is_decoder (bool)
patch_size (int | None)
img_size (int | tuple | None)
in_channels (int)
kwargs (Dict)
Attention Modules¶
Multi-Head Attention (MHA)¶
- class transformer.attns.MHA(d_model, n_heads, dropout=0.0, attn_bias=False, qk_norm=True, layer_idx=0, pos_encoding='RoPE', pos_encoding_kwargs={}, max_seq_len=1024)[source]¶
Bases:
ModuleMulti-Head Attention (MHA) module using optimized scaled_dot_product_attention.
- Parameters:
d_model (int) – Model dimension.
n_heads (int) – Number of attention heads.
d_modelis split acrossn_heads.dropout (float, optional) – Dropout probability on attention weights. Default:
0.0attn_bias (bool, optional) – Whether to use bias in linear projections. Default:
Falseqk_norm (bool, optional) – Whether to apply RMSNorm to queries and keys. Default:
Truelayer_idx (int, optional) – Index of the layer (used for debugging/logging).
pos_encoding (str, optional) – Positional Encoding to use. Default:
RoPEpos_encoding_kwargs (Dict, optional) – Dictionary of additional arguments for positional encoding.
max_seq_len (int) – Maximum sequence length for RoPE.
- supports_cache = True¶
- __init__(d_model, n_heads, dropout=0.0, attn_bias=False, qk_norm=True, layer_idx=0, pos_encoding='RoPE', pos_encoding_kwargs={}, max_seq_len=1024)[source]¶
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- Parameters:
d_model (int)
n_heads (int)
dropout (float)
attn_bias (bool | None)
qk_norm (bool | None)
layer_idx (int)
pos_encoding (str)
pos_encoding_kwargs (Dict)
max_seq_len (int)
- forward(x, mask=None, pos=None, flash_attn=(False, <SDPBackend.FLASH_ATTENTION: 1>, False), return_states=False, cache=None, return_cache=False)[source]¶
Forward pass of MHA.
- Parameters:
x (torch.Tensor) – Input tensor of shape
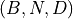 where
where 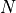 is the sequence length,
is the sequence length,
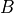 is the batch size, and
is the batch size, and 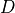 is the embedding dimension
is the embedding dimension d_model.mask (torch.BoolTensor, optional) – Boolean mask preventing attention to certain positions. Shape
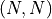 or
or 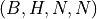 .
True indicates masked positions. When Flash Attention is enabled, it is inverted internally.
.
True indicates masked positions. When Flash Attention is enabled, it is inverted internally.pos (torch.LongTensor, optional) – Position indices for RoPE, shape
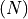 or
or 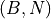
flash_attn (Tuple[bool, Union[list[torch.nn.attention.SDPBackend], torch.nn.attention.SDPBackend], bool], optional) – Tuple controlling Flash Attention usage: - bool: Whether to use Flash Attention. Default:
False- Union[List[SDPBackend], SDPBackend]: Backend(s) for scaled dot product attention - bool: Whether backend order indicates priority. Default:Falsereturn_states (bool, optional) – If
True, return dictionary with intermediate tensors. Default:Falsecache (Tuple[torch.Tensor, torch.Tensor], optional) – Optional KV cache tuple (k_prev, v_prev) of shape (B, H, L_prev, d) each. New keys/values are concatenated with cached ones along sequence dimension.
return_cache (bool, optional) – If True, always return cache tuple. Used for building initial cache.
- Returns:
Output tensor
if not return_states, else dict containing
keys: output, queries, keys, values, attn_weights, attn_scores, output_before_proj, input.
If cache is provided or return_cache=True, returns tuple (output, new_cache).- Return type:
Union[torch.Tensor, Dict, Tuple[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]]
Grouped-Query Attention (GQA)¶
- class transformer.attns.GQA(d_model, n_heads, n_kv_heads, dropout=0.0, attn_bias=False, qk_norm=True, layer_idx=0, pos_encoding='RoPE', pos_encoding_kwargs={}, max_seq_len=1024)[source]¶
Bases:
ModuleGrouped Query Attention (GQA) module using optimized scaled_dot_product_attention.
- Parameters:
d_model (int) – Model dimension.
n_heads (int) – Number of attention heads.
d_modelis split acrossn_heads.n_kv_heads (int) – Number of key/value heads (must divide n_heads).
dropout (float, optional) – Dropout probability on attention weights. Default:
0.0attn_bias (bool, optional) – Whether to use bias in linear projections. Default:
Falseqk_norm (bool, optional) – Whether to apply RMSNorm to queries and keys. Default:
Truelayer_idx (int, optional) – Index of the layer (used for debugging/logging).
pos_encoding (str, optional) – Positional Encoding to use. Default:
RoPEpos_encoding_kwargs (Dict, optional) – Dictionary of additional arguments for positional encoding.
max_seq_len (int) – Maximum sequence length for RoPE.
- supports_cache = True¶
- __init__(d_model, n_heads, n_kv_heads, dropout=0.0, attn_bias=False, qk_norm=True, layer_idx=0, pos_encoding='RoPE', pos_encoding_kwargs={}, max_seq_len=1024)[source]¶
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- Parameters:
d_model (int)
n_heads (int)
n_kv_heads (int)
dropout (float | None)
attn_bias (bool | None)
qk_norm (bool | None)
layer_idx (int)
pos_encoding (str)
pos_encoding_kwargs (Dict)
max_seq_len (int)
- forward(x, mask=None, pos=None, flash_attn=(False, <SDPBackend.FLASH_ATTENTION: 1>, False), return_states=False, cache=None, return_cache=False)[source]¶
Forward pass of GQA.
- Parameters:
x (torch.Tensor) – Input tensor of shape
where is the Sequence Length,
is the batch size, and is the embedding dimension d_model.mask (torch.BoolTensor, optional) – If specified, a 2D or 4D mask preventing attention to certain positions. Must be of shape
or , where is the batch size, 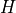 is the number of heads and
is the Sequence Length. A 2D mask will be broadcasted across the batch while a 4D mask allows
for a different mask for each entry in the batch and/or heads dimensions.
Note: Should be a boolean mask where True indicates masked positions.
When Flash Attention is enabled it is inverted because PyTorch expects True for allowed positions.
is the number of heads and
is the Sequence Length. A 2D mask will be broadcasted across the batch while a 4D mask allows
for a different mask for each entry in the batch and/or heads dimensions.
Note: Should be a boolean mask where True indicates masked positions.
When Flash Attention is enabled it is inverted because PyTorch expects True for allowed positions.pos (torch.LongTensor, optional) – Position indices for RoPE, shape
or flash_attn (Tuple[bool, Union[list[torch.nn.attention.SDPBackend], torch.nn.attention.SDPBackend], bool], optional) – Tuple of Arguments for Flash Attention and the Context manager to select which backend to use for scaled dot product attention. - bool: Whether to use or not Flash Attention. Default:
False- Union[List[SDPBackend], SDPBackend]: A backend or list of backends for scaled dot product attention. Default:torch.nn.attention.SPDBackend.FLASH_ATTENTION- bool: Whether the ordering of the backends is interpreted as their priority order. Default:Falsereturn_states (bool, optional) – If
True, return a dictionary of intermediate tensors. Default:Falsecache (Tuple[torch.Tensor, torch.Tensor], optional) – Optional KV cache tuple (k_prev, v_prev) of shape (B, H_kv, L_prev, d) each. For GQA, cache stores compressed key/value heads before repeat_interleave.
return_cache (bool, optional) – If True, always return cache tuple even on first pass. Used for building initial cache.
- Returns:
Output tensor of shape
if not return_states, else a dict containing
the keys: {output, queries, keys, values, attn_weights, attn_scores, output_before_proj and input}.
If cache is provided or return_cache=True, returns a tuple (output, new_cache) where new_cache is (k, v).- Return type:
Union[torch.Tensor, Dict, Tuple[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]]
Cross-Attention¶
- class transformer.attns.CrossAttention(d_model, n_heads, dropout=0.0, attn_bias=False, qk_norm=True, layer_idx=0, pos_encoding='RoPE', pos_encoding_kwargs={}, max_seq_len=1024)[source]¶
Bases:
ModuleCross-Attention module using optimized scaled_dot_product_attention.
- Parameters:
d_model (int) – Model dimension.
n_heads (int) – Number of attention heads.
d_modelis split acrossn_heads.dropout (float, optional) – Dropout probability on attention weights. Default:
0.0attn_bias (bool, optional) – Whether to use bias in linear projections. Default:
Falseqk_norm (bool, optional) – Whether to apply RMSNorm to queries and keys. Default:
Truelayer_idx (int, optional) – Index of the layer (used for debugging/logging).
pos_encoding (str, optional) – Positional Encoding to use. Default:
RoPEpos_encoding_kwargs (Dict, optional) – Dictionary of additional arguments for positional encoding.
max_seq_len (int) – Maximum sequence length for RoPE.
- Note: CrossAttention does not support KV caching. This is a known limitation for
autoregressive decoding with cross-attention.
- __init__(d_model, n_heads, dropout=0.0, attn_bias=False, qk_norm=True, layer_idx=0, pos_encoding='RoPE', pos_encoding_kwargs={}, max_seq_len=1024)[source]¶
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- Parameters:
d_model (int)
n_heads (int)
dropout (float | None)
attn_bias (bool | None)
qk_norm (bool | None)
layer_idx (int)
pos_encoding (str)
pos_encoding_kwargs (Dict)
max_seq_len (int)
- forward(queries, kv, mask=None, pos_q=None, pos_k=None, flash_attn=(False, <SDPBackend.FLASH_ATTENTION: 1>, False), return_states=False)[source]¶
Forward pass of CrossAttention.
- Parameters:
queries (torch.Tensor) – Input tensor of shape
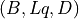 where
where 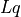 is the Sequence Length for the query sequence,
is the batch size, and is the embedding dimension
is the Sequence Length for the query sequence,
is the batch size, and is the embedding dimension d_model.kv (torch.Tensor) – Input tensor of shape
where 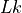 is the Sequence Length for the key/value sequence,
is the batch size, and is the embedding dimension
is the Sequence Length for the key/value sequence,
is the batch size, and is the embedding dimension d_model.mask (torch.BoolTensor, optional) – If specified, a 2D or 4D mask preventing attention to certain positions. Must be of shape
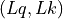 or
or 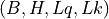 , where is the batch size, is the number of heads,
is the Sequence Length of the query sequence and is the Sequence Length of the key/value sequence.
A 2D mask will be broadcasted across the batch while a 4D mask allows for a different mask for each entry
in the batch and/or heads dimensions.
Note: Should be a boolean mask where True indicates masked positions.
When Flash Attention is enabled it is inverted because PyTorch expects True for allowed positions.
, where is the batch size, is the number of heads,
is the Sequence Length of the query sequence and is the Sequence Length of the key/value sequence.
A 2D mask will be broadcasted across the batch while a 4D mask allows for a different mask for each entry
in the batch and/or heads dimensions.
Note: Should be a boolean mask where True indicates masked positions.
When Flash Attention is enabled it is inverted because PyTorch expects True for allowed positions.pos_q (torch.LongTensor, optional) – Position indices for Queries, shape
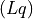 or
or 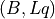
pos_k (torch.LongTensor, optional) – Position indices for Keys, shape
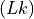 or
or 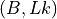
flash_attn (Tuple[bool, Union[list[torch.nn.attention.SDPBackend], torch.nn.attention.SDPBackend], bool], optional) – Tuple of Arguments for Flash Attention and the Context manager to select which backend to use for scaled dot product attention. - bool: Whether to use or not Flash Attention. Default:
False- Union[List[SDPBackend], SDPBackend]: A backend or list of backends for scaled dot product attention. Default:torch.nn.attention.SPDBackend.FLASH_ATTENTION- bool: Whether the ordering of the backends is interpreted as their priority order. Default:Falsereturn_states (bool, optional) – If True, return dictionary of intermediates tensors. Default: False
- Returns:
Output tensor of shape
if not return_states, else a dict containing
the keys: {output, queries, keys, values, attn_weights, attn_scores, output_before_proj and input} where input is a tuple (queries, kv)- Return type:
Union[torch.Tensor, Dict]
Positional Embeddings¶
RoPE (Rotary Position Embedding)¶
- class transformer.pos.RoPE(max_seq_len, d_head, rope_base=10000.0, persistent=True)[source]¶
Bases:
ModuleRotary Position Embedding (RoPE) module.
- Parameters:
max_seq_len (int) – Maximum sequence length for which to precompute frequencies.
d_head (int) – Dimension per head (must be even).
rope_base (float, optional) – Base for the exponential frequency calculation. Default:
10000.0persistent (bool, optional) – Whether to register the precomputed cos/sin as persistent buffers. Default:
True
- __init__(max_seq_len, d_head, rope_base=10000.0, persistent=True)[source]¶
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- Parameters:
max_seq_len (int)
d_head (int)
rope_base (float)
persistent (bool)
- forward(q, k, pos_q, pos_k)[source]¶
Apply rotary position embeddings to queries and keys.
- Parameters:
q (torch.Tensor) – Query tensor of shape
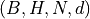
k (torch.Tensor) – Key tensor of shape
pos_q (torch.LongTensor) – Positions for queries, shape
 or
or pos_k (torch.LongTensor) – Positions for keys, shape
or
- Returns:
Rotated queries and keys.
- Return type:
Tuple[torch.Tensor, torch.Tensor]
PartialRoPE¶
- class transformer.pos.PartialRoPE(max_seq_len, d_head, rot_frac=0.5, rope_base=10000.0, persistent=True)[source]¶
Bases:
ModulePartial Rotary Positional Embedding (PartialRoPE).
Applies RoPE to only a fraction of the head dimension while leaving the rest unchanged.
- Parameters:
max_seq_len (int) – Maximum sequence length for which to precompute cos/sin.
d_head (int) – Dimension per head (must be even).
rot_frac (float, optional) – Fraction of head dimensions to rotate in (0, 1]. Default: 0.5
rope_base (float, optional) – Base for the exponential frequency calculation. Default: 10000.0
persistent (bool, optional) – Whether to register cos/sin as persistent buffers. Default: True
- __init__(max_seq_len, d_head, rot_frac=0.5, rope_base=10000.0, persistent=True)[source]¶
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- Parameters:
max_seq_len (int)
d_head (int)
rot_frac (float)
rope_base (float)
persistent (bool)
- forward(q, k, pos_q, pos_k)[source]¶
Apply partial RoPE to queries and keys.
- Parameters:
q (torch.Tensor) – Query tensor of shape
k (torch.Tensor) – Key tensor of shape
pos_q (torch.LongTensor) – Positions for queries, shape
or pos_k (torch.LongTensor) – Positions for keys, shape
or
- Returns:
Rotated queries and keys.
- Return type:
Tuple[torch.Tensor, torch.Tensor]
ALiBi (Attention with Linear Biases)¶
- class transformer.pos.ALiBi(max_seq_len, n_heads, base=2.0, persistent=True)[source]¶
Bases:
ModuleAttention with Linear Biases (ALiBi) per-head bias module.
This module produces additive attention biases that are linear in the relative distance between query and key positions. Biases are computed per-head using a head-specific slope and returned in a shape that can be directly added to attention logits.
The bias for head h and positions i (query) and j (key) is:
B_h[i, j] = -m_h * (i - j)
where m_h is the slope for head h (larger slopes bias attention to local positions). The module returns a tensor of shape (1, n_heads, L, L) so it can be added to logits of shape (B, n_heads, L, L) with broadcasting.
- Parameters:
max_seq_len (int) – nominal maximum sequence length (used for internal checks; biases can be computed for longer sequences on the fly).
n_heads (int) – number of attention heads.
base (float, optional) – base used in slope schedule. Default follows the paper: slopes = 2^{-8 * h / n_heads}.
persistent (bool, optional) – whether to register slopes as persistent buffers.
- __init__(max_seq_len, n_heads, base=2.0, persistent=True)[source]¶
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- Parameters:
max_seq_len (int)
n_heads (int)
base (float)
persistent (bool)
- forward(seq_len, device=None, dtype=None)[source]¶
Return ALiBi bias tensor for a square attention of length seq_len.
- Parameters:
seq_len (int) – sequence length L for which to compute biases.
device (torch.device, optional) – device for the returned tensor. If None, uses the device of the stored slopes buffer.
dtype (torch.dtype, optional) – dtype for the returned tensor. If None, uses the dtype of the stored slopes buffer.
- Returns:
bias tensor of shape (1, n_heads, L, L) with dtype/device as requested. This can be added to attention logits of shape (B, n_heads, L, L).
- Return type:
torch.Tensor
Feed-Forward Modules¶
SwiGLU¶
- class transformer.ffn.SwiGLU(d_model, d_ff, bias=True)[source]¶
Bases:
ModuleSwiGLU feed-forward module
- Parameters:
d_model (int) – Model dimension.
d_ff (int) – Intermediate dimension (should be even, as it’s split into two halves).
bias (bool, optional) – Whether to use bias in linear layers. Default:
True
- __init__(d_model, d_ff, bias=True)[source]¶
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- Parameters:
d_model (int)
d_ff (int)
bias (bool | None)
- forward(x, return_states=False)[source]¶
Forward pass of SwiGLU.
- Parameters:
x (torch.Tensor) – Input tensor of shape
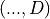
return_states (bool, optional) – If True, return intermediate activations and input. Default:
False
- Returns:
Output tensor
or dict with intermediates states
containing the keys: “output”, “y1”, “y2” and “input”.- Return type:
Union[torch.Tensor, Dict]
MLP¶
- class transformer.ffn.MLP(d_model, d_ff, bias=True)[source]¶
Bases:
ModuleClassic MLP with GELU activation (as used in the original Transformer).
- Parameters:
d_model (int) – Model dimension.
d_ff (int) – Intermediate dimension.
bias (bool, optional) – Whether to use bias in linear layers. Default:
True
- __init__(d_model, d_ff, bias=True)[source]¶
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- Parameters:
d_model (int)
d_ff (int)
bias (bool | None)
- forward(x, return_states=False)[source]¶
Forward pass of MLP.
- Parameters:
x (torch.Tensor) – Input tensor of shape
return_states (bool, optional) – If True, return intermediate activations. Default:
False
- Returns:
Output tensor
or dict with intermediates states
containing the keys: “output”, “h1”, “h2” and “input”.- Return type:
Union[torch.Tensor, Dict]
Transformer Model¶
TransformerBlock¶
- class transformer.transformer.TransformerBlock(config, attn_kwargs={}, ffn_kwargs={}, norm_kwargs={}, layer_idx=0)[source]¶
Bases:
GradientCheckpointingLayerA Single Transformer Decoder Block with support for Gradient Checkpointing consisting of Multi-Head Attention and Feed-Forward layers, each with Pre-Normalization (RMSNorm) and Standard Residual Connections.
- Parameters:
config (TransformerConfig) – Configuration object.
attn_kwargs (Dict, optional) – Additional Arguments for the attention class passed from
TransformerConfig.attn_class. It is only used ifTransformerConfig.attn_classisType[nn.Module]ffn_kwargs (Dict, optional) – Additional Arguments for the ffn class passed from
TransformerConfig.ffn_class. It is only used ifTransformerConfig.ffn_classisType[nn.Module]norm_kwargs (Dict, optional) – Additional Arguments for the normalization class passed from
TransformerConfig.norm_class. It is always passed.layer_idx (int, optional) – Index of this block (used for debugging/logging).
- __init__(config, attn_kwargs={}, ffn_kwargs={}, norm_kwargs={}, layer_idx=0)[source]¶
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- Parameters:
attn_kwargs (Dict | None)
ffn_kwargs (Dict | None)
norm_kwargs (Dict | None)
layer_idx (int)
- forward(x, attn_mask=None, pos=None, flash_attn=(False, <SDPBackend.FLASH_ATTENTION: 1>, False), return_states=False, cache=None, encoder_hidden_states=None, encoder_attn_mask=None, encoder_pos=None, use_cache=None)[source]¶
Forward pass of the transformer block.
- Parameters:
x (torch.Tensor) – Input tensor of shape
.attn_mask (torch.Tensor, optional) – Attention mask for the Attention block.
pos (torch.Tensor, optional) – Position indices for Positional Encoding (RoPE, PartialRoPE, etc.). Shape
or .flash_attn (Tuple[bool, Union[list[torch.nn.attention.SDPBackend], torch.nn.attention.SDPBackend], bool], optional) – Tuple of Arguments for Flash Attention.
return_states (bool, optional) – If True, return a dictionary of intermediate outputs. Default: False
cache (Tuple[torch.Tensor, torch.Tensor], optional) – Optional KV cache tuple (k_prev, v_prev) for incremental decoding. Only used by MHA and GQA attention types.
encoder_hidden_states (torch.Tensor, optional) – Encoder output tensor of shape
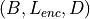 .
Only used when this block has CrossAttention.
.
Only used when this block has CrossAttention.encoder_attn_mask (torch.Tensor, optional) – Attention mask for cross-attention to encoder.
encoder_pos (torch.Tensor, optional) – Position indices for encoder hidden states (used by CrossAttention).
use_cache (bool, optional) – Whether to return KV cache. Defaults to None which uses config setting.
- Returns:
Output tensor of shape
if not return_states and no cache,
else a dict containing the keys: “output”, “attn_output” and “ffn_output”.
If use_cache is True or cache is provided, returns a tuple (output, new_cache).- Return type:
Union[torch.Tensor, Tuple[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]], Dict]
Transformer Class (Main Model)¶
- class transformer.transformer.Transformer(config, attn_kwargs={}, pos_encoding_kwargs={}, ffn_kwargs={}, norm_kwargs={})[source]¶
Bases:
PreTrainedModel,GenerationMixinTransformer language model, compatible with the HuggingFace interface.
- Parameters:
config (TransformerConfig) – Model configuration.
attn_kwargs (Dict, optional) – Additional Keyword Arguments passed to the Attention Module. Default:
{"pos_encoding_kwargs": **pos_encoding_kwargs}pos_encoding_kwargs (Dict, optional) – Additional Arguments for Positional Encoding. Default:
{}Example:{"rope_base": 12000, "persistent": False}ffn_kwargs (Dict, optional) – Additional Keyword Arguments passed to the Feed-Forward Module. Default:
{}norm_kwargs (Dict, optional) – Additional Keyword Arguments passed to the Normalization Layer. Default:
{}patch_size (Optional[int], optional) – Patch size for Vision Transformer (ViT) compatibility. If specified, adds a patch embedding layer.
img_size (Optional[Union[int, Tuple[int, int]]], optional) – Image size for ViT compatibility. Used with patch_size to compute number of patches.
num_channels (int, optional) – Number of input channels for ViT. Default: 3 (RGB).
- config_class¶
alias of
TransformerConfig
- base_model_prefix: str = 'transformer'¶
- supports_gradient_checkpointing: bool = True¶
- input_modalities: str | list[str] = ['text', 'image']¶
- __init__(config, attn_kwargs={}, pos_encoding_kwargs={}, ffn_kwargs={}, norm_kwargs={})[source]¶
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- Parameters:
attn_kwargs (Dict)
pos_encoding_kwargs (Dict)
ffn_kwargs (Dict)
norm_kwargs (Dict)
- forward(input_ids=None, images=None, labels=None, is_causal=True, attn_mask=None, pos=None, flash_attn=(False, <SDPBackend.FLASH_ATTENTION: 1>, False), return_states=False, loss_kwargs={}, past_key_values=None, use_cache=None, encoder_hidden_states=None, encoder_attn_mask=None, **kwargs)[source]¶
Forward pass of the Transformer model.
- Parameters:
input_ids (torch.LongTensor, optional) – Token indices of shape
for text input. Required for text modality.images (torch.Tensor, optional) – Image tensor of shape
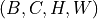 for vision input. Required for image modality.
for vision input. Required for image modality.labels (torch.LongTensor, optional) – Target token indices for loss computation, same shape as input_ids.
is_causal (bool, optional) – If True, create a causal attention mask. Default: True
attn_mask (torch.Tensor, optional) – Custom attention mask. If None and is_causal, a upper triangular causal mask is generated.
pos (torch.Tensor, optional) – Position indices. If None, computed from sequence length or cache length.
flash_attn (Tuple[bool, Union[list[torch.nn.attention.SDPBackend], torch.nn.attention.SDPBackend], bool], optional) – Tuple of Arguments for Flash Attention.
return_states (bool, optional) – If True, return hidden states of all layers. Default: False
loss_kwargs (Dict, optional) – Additional keyword arguments passed to F.cross_entropy for loss computation.
past_key_values (Tuple[Tuple[torch.Tensor, torch.Tensor], ...], optional) – Pre-computed KV cache from previous generation steps. Tuple of tuples, one per layer, each containing (key, value) tensors of shape (B, H, L, d).
use_cache (bool, optional) – Whether to use KV cache. Defaults to config.use_cache if not specified.
encoder_hidden_states (torch.Tensor, optional) – Encoder output for encoder-decoder models.
encoder_attn_mask (torch.Tensor, optional) – Mask for encoder hidden states.
kwargs (Dict, optional) – Additional keyword arguments
- Returns:
CausalLMOutput containing loss (if labels given), logits, and optionally past_key_values and hidden_states.
- Return type:
CausalLMOutput
Note
Either
input_ids(for text) orimages(for vision) must be provided. The model automatically detects the modality based on which input is provided.
- set_input_embeddings(embeddings)[source]¶
Set the input embeddings layer.
- Parameters:
embeddings (Embedding)
- classmethod from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)[source]¶
Load a pretrained model from a local directory or HuggingFace Hub.
- Parameters:
pretrained_model_name_or_path (str) – Path to local model directory or HF Hub model ID.
model_args (tuple) – Additional positional arguments passed to PreTrainedModel.from_pretrained.
kwargs (dict) – Additional keyword arguments passed to PreTrainedModel.from_pretrained.
- Returns:
Loaded Transformer model.
- Return type:
- push_to_hub(repo_id, config=None, commit_message='Push model to hub', private=False, token=None, max_shard_size='5GB', **kwargs)[source]¶
Push the model and its configuration to the HuggingFace Hub.
- Parameters:
repo_id (str) – Repository ID on the Hub (e.g., "username/my-model").
config (PretrainedConfig, optional) – Optional config object. If None, uses self.config.
commit_message (str, optional) – Commit message for the upload. Default: "Push model to hub"
private (bool, optional) – Whether to create a private repository. Default: False
token (str, optional) – HuggingFace API token. If None, uses cached token.
max_shard_size (str, optional) – Maximum size per shard when sharding. Default: "5GB"
kwargs (dict) – Additional keyword arguments passed to PreTrainedModel.push_to_hub.
- Returns:
URL to the uploaded model repository.
- Return type:
str
EncoderDecoderModel¶
- class transformer.encoder_decoder.EncoderDecoderModel(encoder_config, decoder_config)[source]¶
Bases:
Module,GenerationMixinEncoder-Decoder Transformer model for seq2seq tasks.
Uses a Transformer encoder and decoder with cross-attention support.
- Parameters:
encoder_config (TransformerConfig) – Configuration for the encoder.
decoder_config (TransformerConfig) – Configuration for the decoder.
- __init__(encoder_config, decoder_config)[source]¶
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- Parameters:
encoder_config (TransformerConfig)
decoder_config (TransformerConfig)
- encode(input_ids, attention_mask=None, return_dict=True)[source]¶
Encode source sequences.
- Parameters:
input_ids (torch.Tensor) – Source token IDs of shape (B, L_enc).
attention_mask (torch.Tensor, optional) – Attention mask for encoder (1 for valid, 0 for padding).
return_dict (bool, optional) – If True, return dict; else return tuple. Default: True
- Returns:
Encoder hidden states of shape (B, L_enc, D).
- Return type:
Union[Tuple[torch.Tensor], Dict]
- decode(input_ids, encoder_hidden_states, encoder_attention_mask=None, past_key_values=None, use_cache=True, return_dict=True)[source]¶
Decode target sequences with cross-attention to encoder outputs.
- Parameters:
input_ids (torch.Tensor) – Target token IDs of shape (B, L_dec).
encoder_hidden_states (torch.Tensor) – Encoder output of shape (B, L_enc, D).
encoder_attention_mask (torch.Tensor, optional) – Encoder attention mask.
past_key_values (Tuple[Tuple[torch.Tensor, torch.Tensor]], optional) – KV cache from previous decoding steps.
use_cache (bool, optional) – Whether to use KV cache. Default: True
return_dict (bool, optional) – If True, return dict; else return tuple. Default: True
- Returns:
Decoder logits and optionally past_key_values.
- Return type:
Union[Tuple[torch.Tensor], CausalLMOutput]
- forward(input_ids, encoder_input_ids, encoder_attention_mask=None, labels=None, past_key_values=None, use_cache=True, return_dict=True, **kwargs)[source]¶
Full forward pass through encoder-decoder model.
- Parameters:
input_ids (torch.Tensor) – Target token IDs of shape (B, L_dec).
encoder_input_ids (torch.Tensor) – Source token IDs of shape (B, L_enc).
encoder_attention_mask (torch.Tensor, optional) – Encoder attention mask (1 for valid, 0 for padding).
labels (torch.Tensor, optional) – Target labels for loss computation.
past_key_values (Tuple[Tuple[torch.Tensor, torch.Tensor]], optional) – KV cache for incremental decoding.
use_cache (bool, optional) – Whether to use KV cache. Default: True
return_dict (bool, optional) – If True, return CausalLMOutput; else return tuple. Default: True
- Returns:
Model output with logits and optionally loss.
- Return type:
CausalLMOutput
- prepare_inputs_for_generation(input_ids, past_key_values=None, attention_mask=None, encoder_attention_mask=None, encoder_hidden_states=None, **kwargs)[source]¶
Prepare inputs for generation using HuggingFace’s GenerationMixin.
- Parameters:
input_ids (torch.LongTensor) – Current token IDs.
past_key_values (Optional[Tuple[Tuple[torch.Tensor, torch.Tensor]]]) – Cached key/value states from previous steps.
attention_mask (Optional[torch.Tensor]) – Decoder attention mask.
encoder_attention_mask (Optional[torch.Tensor]) – Encoder attention mask.
encoder_hidden_states (Optional[torch.Tensor]) – Pre-computed encoder outputs.
kwargs – Additional keyword arguments.
- Returns:
Dictionary of inputs for the forward method.
- Return type:
Dict
LoRA (Parameter-Efficient Fine-Tuning)¶
LoRALinear¶
- class transformer.lora.LoRALinear(original_layer, lora_rank=8, lora_alpha=16, lora_dropout=0.0)[source]¶
Bases:
ModuleA thin wrapper around nn.Linear that adds LoRA (Low-Rank Adaptation) adapters.
The original linear layer is kept frozen, and two low-rank trainable matrices (lora_A and lora_B) are added. The output is computed as:
output = W_original @ x + (lora_B @ lora_A) @ x * scaling
- Parameters:
original_layer (nn.Linear) – The original nn.Linear layer to wrap.
lora_rank (int, optional) – Rank of the LoRA decomposition. Default: 8
lora_alpha (int, optional) – Scaling factor for LoRA weights. Default: 16
lora_dropout (float, optional) – Dropout probability for LoRA layers. Default: 0.0
apply_lora_to_model¶
- transformer.lora.apply_lora_to_model(model, target_modules, lora_rank=8, lora_alpha=16, lora_dropout=0.0)[source]¶
Recursively walks the model’s module tree and replaces every nn.Linear whose attribute name matches any string in target_modules with a LoRALinear wrapper.
After replacement, freeze all parameters except those with ‘lora_A’ or ‘lora_B’ in their name to make the model ready for parameter-efficient fine-tuning.
- Parameters:
model (nn.Module) – The PyTorch model to modify.
target_modules (List[str]) – List of exact attribute names to target (e.g., [‘qkv_proj’, ‘W1’]). Modules whose names exactly match any of these strings will be wrapped. Note: This uses full name matching, not substring matching.
lora_rank (int, optional) – Rank of the LoRA decomposition. Default: 8
lora_alpha (int, optional) – Scaling factor for LoRA weights. Default: 16
lora_dropout (float, optional) – Dropout probability for LoRA layers. Default: 0.0
- Returns:
The modified model with LoRA adapters applied.
- Return type:
nn.Module
Example:
# Apply LoRA to query/key/value projections model = Transformer(config) apply_lora_to_model(model, target_modules=['qkv_proj'], lora_rank=8, lora_alpha=16) # Freeze base model, only train LoRA parameters for param in model.parameters(): param.requires_grad = False for name, param in model.named_parameters(): if 'lora_' in name: param.requires_grad = True
Utilities¶
- class transformer.utils.LayerType(*values)[source]¶
Bases:
EnumType enumeration for layer configuration resolution.
- STRING = 1¶
- NN_MODULE = 2¶
- LIST = 3¶
- transformer.utils.get_layer_type(x)[source]¶
Determine the type of a layer configuration value.
This replaces the fragile integer-based check_type function with a robust Enum-based approach.
- Parameters:
x (Union[Type[nn.Module], str, List]) – Object to check (should be a string, nn.Module subclass, or list)
- Returns:
LayerType.STRING if string, LayerType.NN_MODULE if nn.Module subclass, LayerType.LIST if list
- Return type:
- Raises:
TypeError – If x is not a valid type
- transformer.utils.resolve_layer_config(config_value, layer_idx, n_layers)[source]¶
Resolve configuration value for a specific layer index. Supports both uniform (single value) and per-layer (list) configurations.
- Parameters:
config_value (Union[str, Type[nn.Module], List]) – Configuration value (string, type, or list)
layer_idx (int) – Index of the current layer
n_layers (int) – Total number of layers
- Returns:
Resolved configuration value for this layer
- Raises:
ValueError – If list length doesn’t match n_layers